WebMagic
介绍
WebMagic 是一个简单灵活的 Java 爬虫框架,基于流行的爬虫工具 Scrapy 的设计思想实现。它提供了爬虫开发的核心功能,并遵循"微内核+插件"的设计模式,使得开发者可以灵活扩展功能。
主要特点
- 简单易用:提供简洁的 API,只需少量代码即可实现一个功能强大的爬虫
- 模块化设计:核心框架小,通过扩展机制满足不同需求
- 强大的抽取功能:支持 XPath、正则表达式等多种方式提取数据
- 多线程支持:内置多线程支持,提高爬取效率
- 可扩展性:可以方便地扩展和定制各个组件
底层原理
HttpClient+Jsoup
在爬虫应用中,HttpClient和Jsoup通常协同工作:
- HttpClient负责网络通信层:发送HTTP请求、接收响应、处理重定向/认证等
- Jsoup负责内容解析层:将获取的HTML转换为DOM树,提供便捷的数据提取API
- 这种分层设计符合单一职责原则,使爬虫程序结构更清晰
WebMagic的执行过程
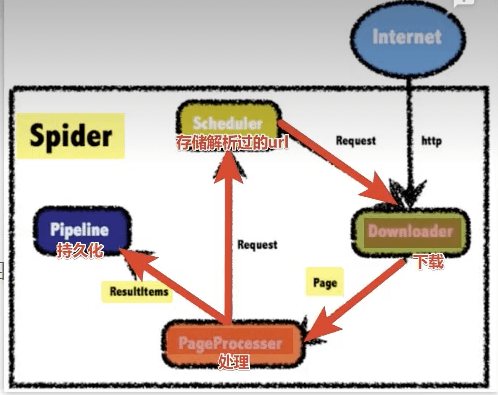
代码案例
1.创建一个Maven项目,引入依赖
<dependency>
<groupId>us.codecraft</groupId>
<artifactId>webmagic-core</artifactId>
<version>1.0.3</version>
</dependency>
<dependency>
<groupId>us.codecraft</groupId>
<artifactId>webmagic-extension</artifactId>
<version>1.0.3</version>
</dependency>
2.重写PageProcessor接口,爬去csdn主页的数据信息
package com.luochen.processer;
import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.Spider;
import us.codecraft.webmagic.processor.PageProcessor;
public class MyPageProcesser implements PageProcessor {
/*
* 处理解析页面
* */
@Override
public void process(Page page) {
System.out.println(page.getHtml().toString());
}
/*
* 站点处理:超时的时间,重试的次数
* */
@Override
public Site getSite() {
return Site.me()
.setSleepTime(300)//爬虫休息时间,ms
.setTimeOut(3000)//设置超时时间
.setRetryTimes(3); //设置重试次数
}
public static void main(String[] args) {
Spider.create(new MyPageProcesser())
.addUrl("https://www.csdn.net") //加入爬取链接
.start(); //开始爬虫
}
}
运行输出结果如下:
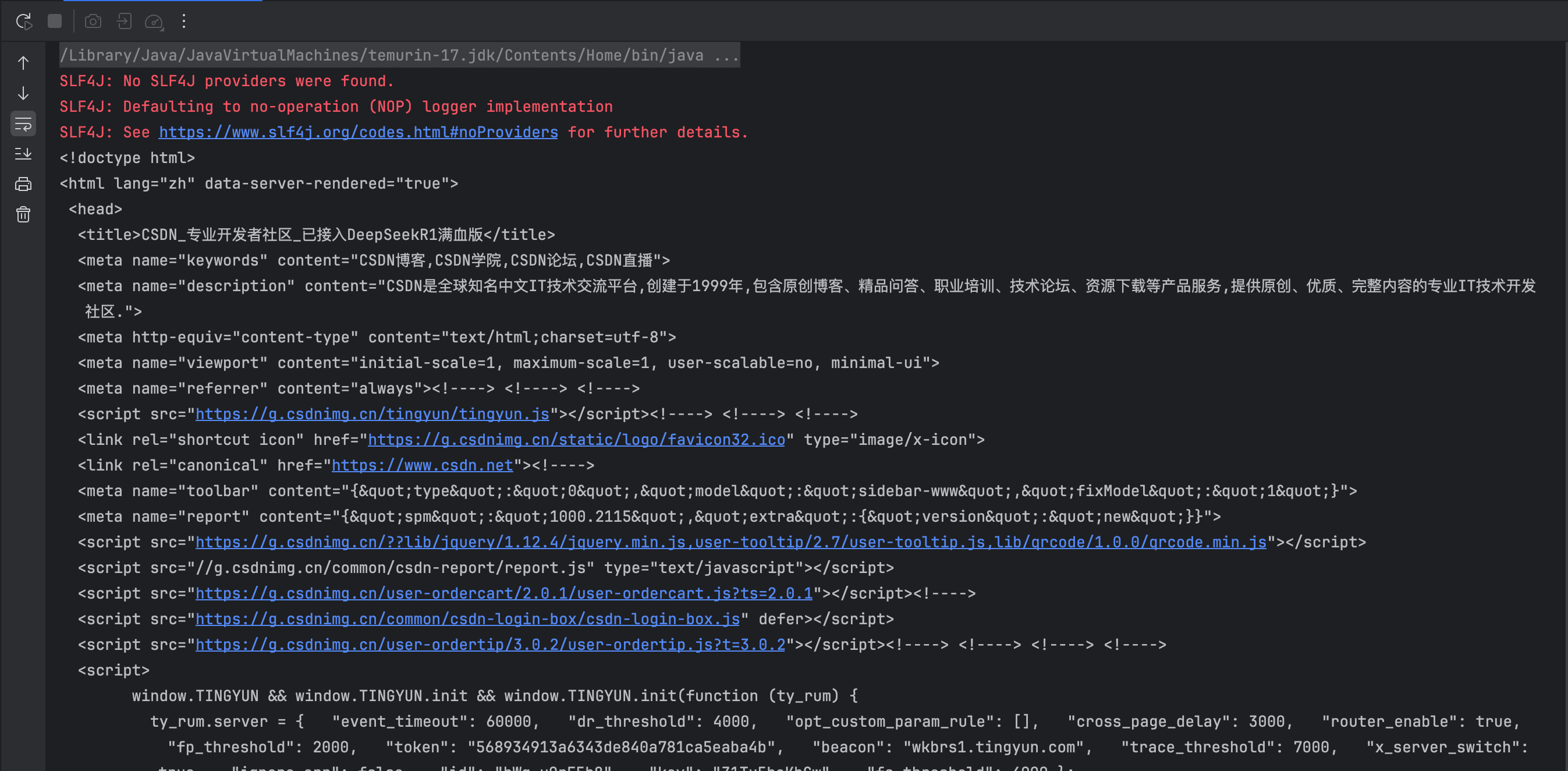
获取爬虫数据
xpath:
XPath(XML Path Language)是一种用于在XML和HTML文档中定位和选择节点的查询语言。它提供了一种在文档层次结构中导航的方式,类似于文件系统中的路径。
案例分析
<html>
<body>
<div id="content">
<h1>Welcome</h1>
<div class="articles">
<article class="post">
<h2>Article 1</h2>
<p>Content 1</p>
<a href="/read-more/1">Read more</a>
</article>
<article class="post">
<h2>Article 2</h2>
<p>Content 2</p>
<a href="/read-more/2">Read more</a>
</article>
</div>
</div>
</body>
</html>
示例1:获取所有文章标题
//article/h2/text()
结果:
- "Article 1"
- "Article 2"
示例2:获取第二篇文章的链接
xpath
(//article)[2]/a/@href
结果:
- "/read-more/2"
示例3:获取包含"Content"文本的段落
xpath
//p[contains(text(), 'Content')]
{% label 注意:xpath的表达式看懂即可,不需要硬记,可通过粘贴复制的方式,如csdn官网,直接复制: red %}
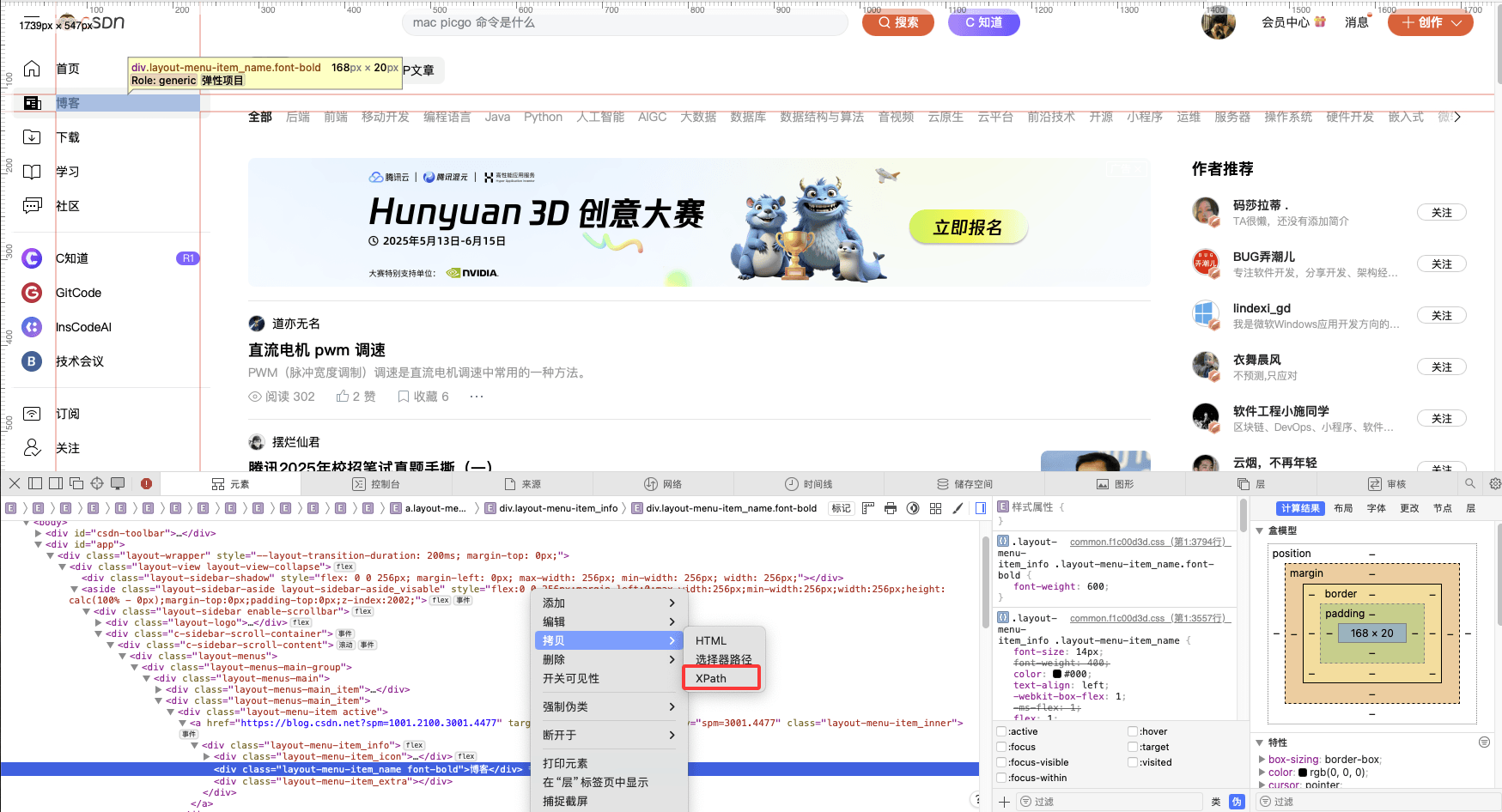
采集爬虫内容
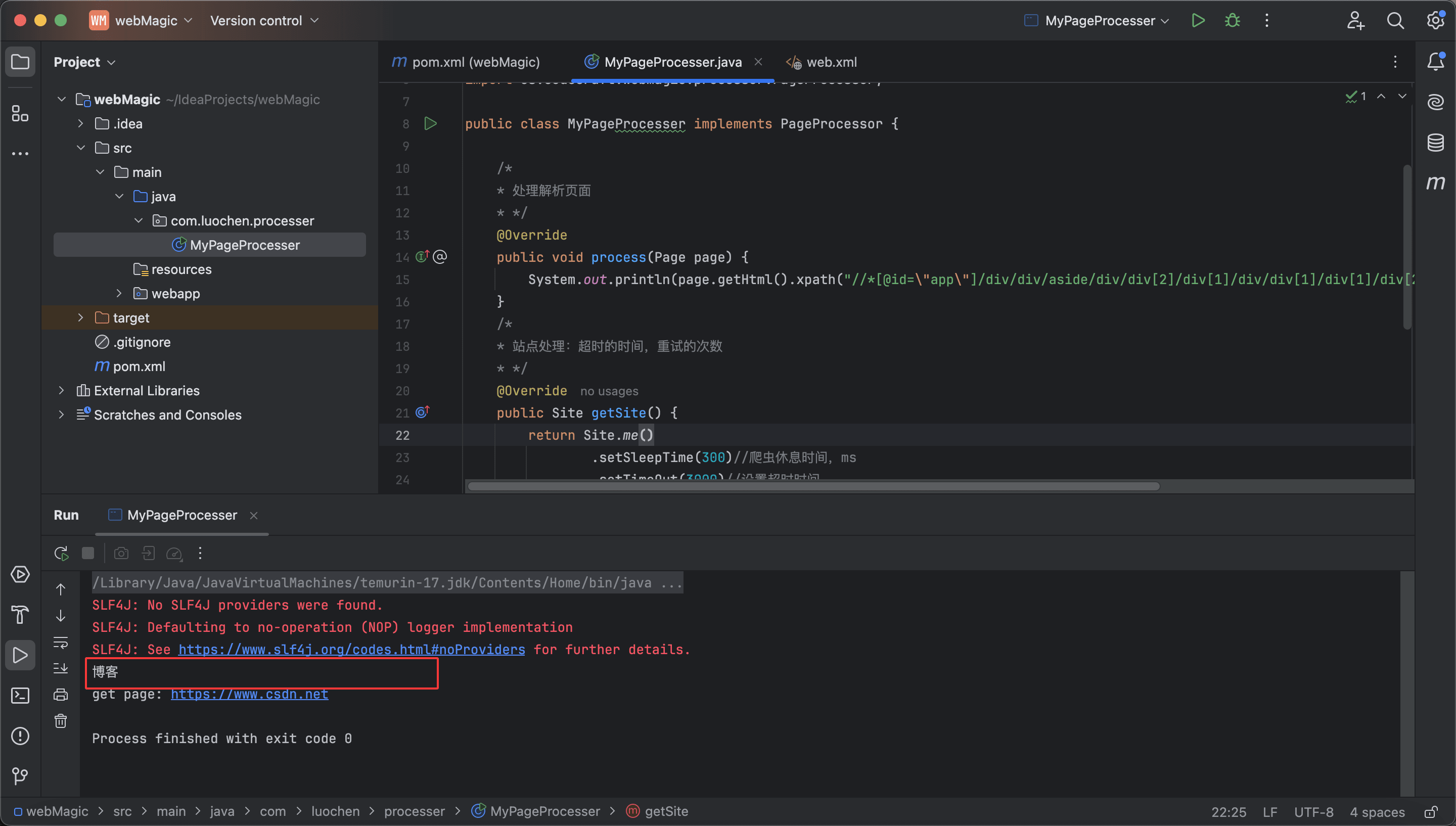
上述粘贴的内容为://*@id="app"/div/div/aside/div/div2/div1/div/div1/div1/div2/div/a/div/div2/
package com.luochen.processer;
import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.Spider;
import us.codecraft.webmagic.processor.PageProcessor;
public class MyPageProcesser implements PageProcessor {
/*
* 处理解析页面
* */
@Override
public void process(Page page) {
System.out.println(page.getHtml().xpath("//*[@id=\"app\"]/div/div/aside/div/div[2]/div[1]/div/div[1]/div[1]/div[2]/div/a/div/div[2]/text()").toString());
}
/*
* 站点处理:超时的时间,重试的次数
* */
@Override
public Site getSite() {
return Site.me()
.setSleepTime(300)//爬虫休息时间,ms
.setTimeOut(3000)//设置超时时间
.setRetryTimes(3); //设置重试次数
}
public static void main(String[] args) {
Spider.create(new MyPageProcesser())
.addUrl("https://www.csdn.net") //加入爬取链接
.run(); //开始爬虫
}
}
实际输出结果:
评论区
评论加载中...